Truck Bed Ski Rack

Unhappy with any existing custom options I set out to design a ski storage system for in my truck bed with a folding tonneau cover. My requirements were: At first I considered just using my Thule roof racks and somehow Read More
Unhappy with any existing custom options I set out to design a ski storage system for in my truck bed with a folding tonneau cover. My requirements were: At first I considered just using my Thule roof racks and somehow Read More
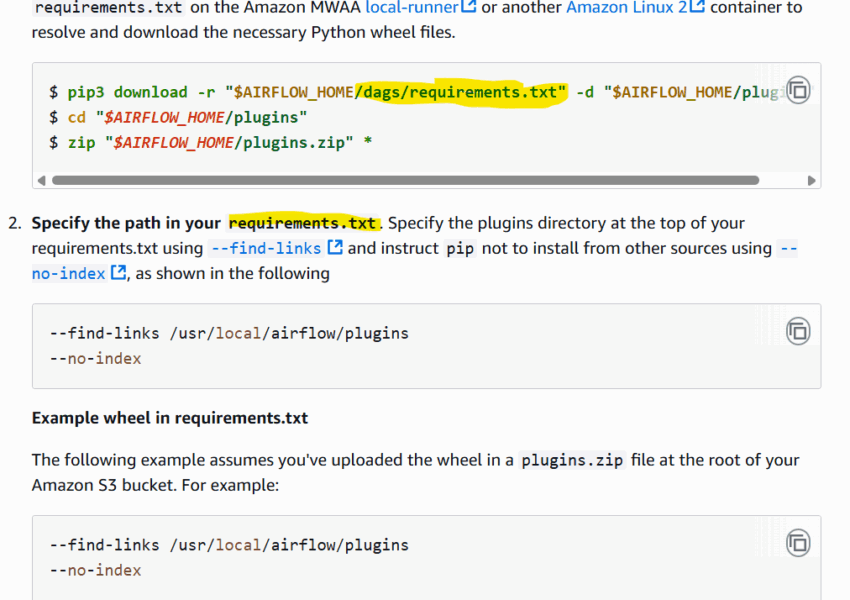
Our team had avoided this for a while but some unknown changes meant the Airflow MWAA requirements install could no longer install packages from PyPi (option 1) and we had to finally solve building the plugins.zip file to include all Read More

After moving I was left with just one gas BBQ, and finally got setup with a new Oklahoma Joe’s offset smoker. I knew there were a lot of suggested improvements for these lower-end models (ex: https://www.youtube.com/watch?v=6CstFU78PgY&t=292s) and after watching several Read More

This spring we saw the Costco Yardistry Gazebo for a great deal in the store, and a good challenge to assemble in 3 days while visiting extended family. This isn’t a full assembly guide but a highlight of helpful steps Read More

We didn’t want just any firepit, we wanted one that looked great. The nice ones are very expensive, the cheap ones would do but look cheap, and the project ones I saw also used expensive custom parts. My goal was Read More
One of many “my wife saw it on Pinterest” projects – next was a Dutch door project at the bottom of our stairs at the entry to the basement. Having the dutch door here will act as a baby/dog gate, Read More
I started working on setting up OpenHab as a home automation hub using an old laptop and a Z-Stick. My main requirement is to be able to hook up my thermostat, as everything Z-Wave looks pretty straightforward. My thermostat is Read More
After using Slack for about a week or so, I was suddenly greeted by a corporate IT policy that blocked the domain… Bored of not having it I found a way this morning to selectively send my slack.com traffic through an Read More
I’d heard the term “Dark Social” on a client call about two months ago, I googled it and balked at the definition. “Dark social describes any web traffic that’s not attributed to a known source” Allegedly coined by this article http://www.theatlantic.com/technology/archive/2012/10/dark-social-we-have-the-whole-history-of-the-web-wrong/263523/, which Read More
Cross Origin Resource Sharing (CORS) is intended to be revolutionary, empowering the web to push and pull data from everywhere. In reality I see this causing more problems than helping anyone. Note: I’ll use XMLHTTP instead of AJAX since the Read More