Build plugins.zip file for Airflow Requirements
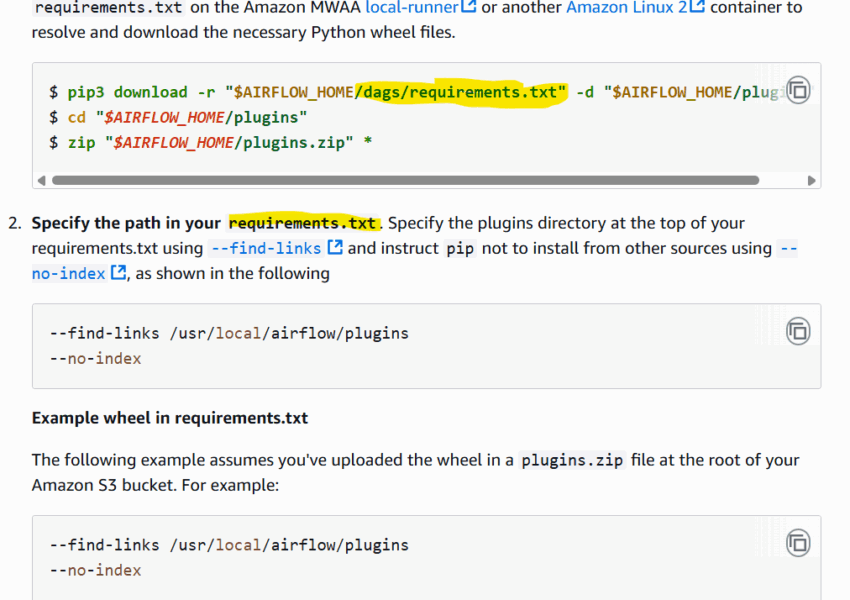
Our team had avoided this for a while but some unknown changes meant the Airflow MWAA requirements install could no longer install packages from PyPi (option 1) and we had to finally solve building the plugins.zip file to include all Read More


